Classification supervisée et non supervisée en Télédétection
Lorsqu’on parle de classes, il faut faire la distinction entre des classes d’information et des classes spectrales. Les classes d’information sont des catégories d’intérêt que l’analyste tente d’identifier dans les images, comme différents types de cultures, de forêts ou d’espèce d’arbres, différents types de caractéristiques géologiques ou de roches, etc. Les classes spectrales sont des groupes de pixels qui ont les mêmes caractéristiques (ou presque) en ce qui a trait à leur valeur d’intensité dans les différentes bandes spectrales des données. L’objectif ultime de la classification est de faire la correspondance entre les classes spectrales et les classes d’information. Il est rare qu’une correspondance directe soit possible entre ces deux types de classes. Des classes spectrales bien définies peuvent apparaître parfois sans qu’elles correspondent nécessairement à des classes d’information intéressantes pour l’analyse. D’un autre côté, une classe d’information très large (par exemple la forêt) peut contenir plusieurs sous-classes spectrales avec des variations spectrales définies. En utilisant l’exemple de la forêt, les sous-classes spectrales peuvent être causées par des variations dans l’âge, l’espèce, la densité des arbres ou simplement par les effets d’ombrage ou des variations dans l’illumination. L’analyste a le rôle de déterminer de l’utilité des différentes classes spectrales et de valider leur correspondance à des classes d’informations utiles. Les méthodes de seuillage bien qu’intéressante s restent insuffisantes dans de nombreux cas. Il faut donc utiliser des méthodes un peu plus élaborées pour améliorer la précision de la classification.
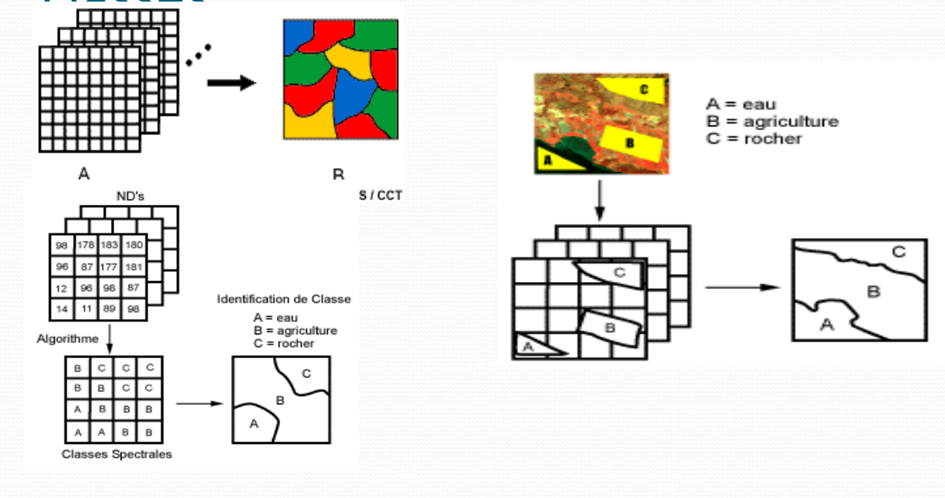
Les méthodes de classification les plus communes peuvent être séparées en deux grandes catégories : les méthodes de classification supervisée et les méthodes de classification non supervisée. Lors de l’utilisation d’une méthode de classification supervisée, l’analyste identifie des échantillons assez homogènes de l’image qui sont représentatifs de différents types de surfaces (classes d’information). Ces échantillons forment un ensemble de données- tests. La sélection de ces données-tests est basée sur les connaissances de l’analyste, sa familiarité avec les régions géographiques et les types de surfaces présents dans l’image. L’analyste supervise donc la classification d’un ensemble spécifique de classes. Les informations numériques pour chacune des bandes et pour chaque pixel de ces ensembles sont utilisées pour que l’ordinateur puisse définir les classes et ensuite reconnaître des régions aux propriétés similaires à chaque classe. L’ordinateur utilise un programme spécial ou algorithme afin de déterminer la « signature » numérique de chacune des classes. Plusieurs algorithmes différents sont possibles. Une fois que l’ordinateur a établi la signature spectrale de chaque classe à la classe avec laquelle il a le plus d’affinités. Une classification supervisée commence donc par l’identification des classes d’information qui sont ensuite utilisées pour définir les classes spectrales qui les représentent.
Classification Non supervisée • La classification non supervisée procède de la façon contraire. Les classes spectrales sont formées en premier, basées sur l’information numérique des données seulement. Ces classes sont ensuite associées, par un analyste, à des classes d’information utile (si possible). Des programmes appelés algorithmes de classification sont utilisés pour déterminer les groupes statistiques naturels ou les structures des données. Habituellement, l’analyste spécifie le nombre de groupes ou classes qui seront formés avec les données. De plus, l’analyste peut spécifier certains paramètres relatifs à la distance entre les classes et la variance à l’intérieur même d’une classe. Le résultat final de ce processus de classification itératif peut créer des classes que l’analyste voudra combiner, ou des classes qui devraient être séparées de nouveau. Chacune de ces étapes nécessite une nouvelle application de l’algorithme. L’intervention humaine n’est donc pas totalement exempte de la classification non supervisée. Cependant, cette méthode ne commence pas avec un ensemble prédéterminé de classes comme pour la classification supervisée. Classification Non supervisée • Dans les méthodes de classification non supervisée, le traitement se fait uniquement sur les données numériques de l’image : il n’y a pas de classes définies a priori dès le départ. Une fois la segmentation effectuée • Les étapes de la classification sont modélisées sur un diagramme, appelé dendrogramme : on peut y identifier les classes qui ont fusionné pour créer une classe plus importante et évaluer la distance entre les différentes classes (deux classes extrêmement éloignées tarderont à être réunies dans une classe plus importante). • L’analyse de ce diagramme peut aider à déterminer le nombre de classes le plus intéressant à obtenir, par visualisation du résultat sur l’image, notamment
Classification supervisée Sans doute la plus utilisée, la classification par maximum de vraisemblance découle d’une méthode probabiliste : pour chaque pixel on détermine sa probabilité d’appartenir à une classe plutôt qu’à une autre. On s’appuie sur la règle de Bayes : P(Ci/p)= P(p/Ci)*P(Ci)/P(p), avec P(Ci/p) = probabilité d’être dans la classe i sachant qu’on est le pixel p, P(p/Ci) = probabilité d’être le pixel p sachant qu’on se trouve dans la classe i, P(Ci) = probabilité d’appartenir à la classe i et P(p) = probabilité d’être le pixel p. On affecte donc p à la classe i si P(p /Ci)*P(Ci)> P(p/Cj)*P(Cj) pour toute classe j.

référence:
- http://www.agerinfo.fr/supports/cours/teledetection/cours
Centre Canadien de Télédétection - http://cct.rncan.gc.ca/resource/index_f.php
- Cours de la NASA (National Aeronautics and Space
- Pr Moupo Moise