Échantillonnage, collecte et classification des données
Le mot « statistiques » est dérivé du mot latin « statut », du mot italien « étatiste », du mot allemand « statistique » et du mot français « statistique », chacun donnant le même sens d’« État politique ». Les concepts et méthodes statistiques sont appliqués dans de nombreux domaines tels que la science, les prévisions météorologiques, les recensements et le marketing, pour n’en citer que quelques-uns. Lorsque le mot « statistiques » est utilisé dans un contexte singulier, il peut être défini comme une méthode scientifique utilisée pour collecter, analyser et interpréter des données et tirer une conclusion ou une comparaison. Lorsqu’il est utilisé au pluriel, il peut être défini comme une donnée à la fois qualitative et quantitative.
Recensement
Un recensement est une étude statistique dans laquelle toutes les personnes du groupe sont interrogées.
Le recensement du Cameroun :
Tous les dix ans, en principe, le gouvernement du Cameroun devrait entreprendre d’énorme tâche de compter le nombre d’habitants du pays. Des questionnaires disponibles en ligne et des démarches porte-à-porte effectuées par les employés du Bureau du recensement sont utilisés pour collecter les données. Les résultats du recensement sont utilisés pour déterminer la répartition géographique de la population afin d’attribuer une représentation appropriée à la Chambre des représentants et un financement pour chaque région.
Échantillon
Un échantillon est une étude statistique dans laquelle seule une partie du groupe est interrogée. Le « Nielson Ratings » est le système utilisé pour mesurer la taille et le type d’audience qui regarde des programmes de télévision spécifiques aux États-Unis. Les téléspectateurs démographiques présélectionnés fournissent des informations sur les émissions, les réseaux et les heures de visionnage.
Conditions requises pour un échantillonnage :
- Caractère aléatoire : chaque élément de l’ensemble universel ou de la population a une chance égale d’être sélectionné.
- Une quantité suffisante d’éléments de la population doit être échantillonnée.
- Fiabilité ou équité – déterminée par l’ampleur de l’erreur d’échantillonnage autorisée par l’étude
Données
Les données sont constituées d’informations associées.
Les données collectées pour la première fois par un enquêteur sont appelées données primaires et les données collectées à partir d’enregistrements ou d’études antérieurs sont appelées données secondaires.
Modes de collecte de données :
1. Entretiens – l’un des moyens les plus rapides de collecter des données
2. Enquêtes écrites – peuvent couvrir une vaste zone géographique (Cependant, les questionnaires envoyés par courrier reçoivent le moins de commentaires. Seules les personnes ayant des opinions très tranchées ont tendance à répondre aux questionnaires.)
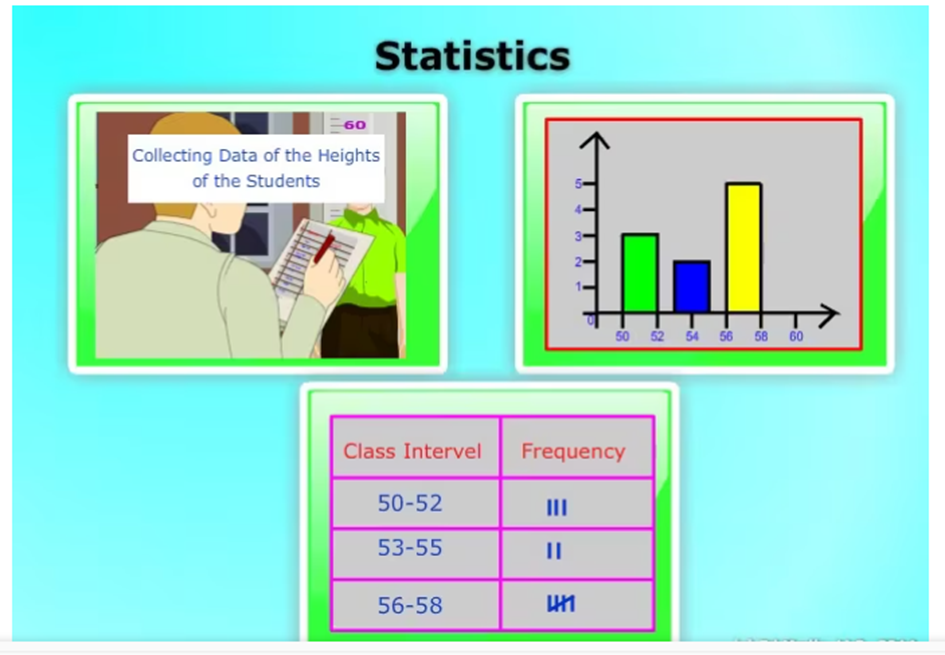
Classification des données
La classification des données est le processus de tri et d’organisation des données sur la base de caractéristiques uniformes ou homogènes.
Il existe quatre types différents de classification des données :
1. Classification géographique : les données sont classées par zone, telle que pays, état, district ou zone.
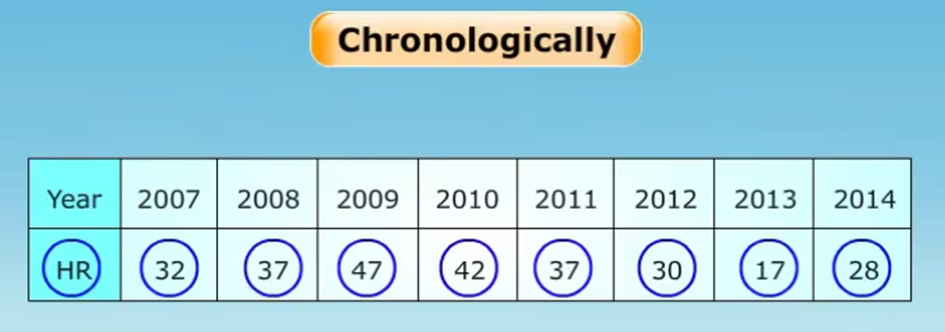
2. Classification chronologique : les données sont classées par périodes de temps, telles que semaines, mois ou années.
3. Classification qualitative : Les données sont classées selon une qualité ou un attribut, tel que la couleur des yeux ou la matière préférée à l’école.