La Classification Supervisée et non Supervisée en Télédétection
Introduction
La télédétection est devenue une discipline clé dans la gestion de l’environnement, l’agriculture, la planification urbaine, la cartographie des ressources naturelles, et bien d’autres domaines. Elle consiste à observer la Terre à distance à l’aide de capteurs embarqués sur des satellites, avions ou drones. Ces capteurs fournissent des images multispectrales ou hyperspectrales qui révèlent des informations précieuses sur la composition et l’état des surfaces terrestres.
Cependant, pour exploiter ces images, il est nécessaire de les analyser et de les classifier afin de reconnaître et distinguer différentes classes d’occupation du sol : forêts, zones urbaines, cours d’eau, sols agricoles, etc. Parmi les nombreuses techniques d’analyse d’images, la classification supervisée est l’une des plus utilisées en télédétection.
Dans cet article, nous allons explorer en profondeur ce qu’est la classification supervisée, son fonctionnement, ses étapes clés, ses avantages, ses limites, ainsi que ses applications concrètes. Nous aborderons aussi les outils et méthodes courantes pour la réaliser efficacement.
Classification Supervisée ?
1.1. Définition
La classification supervisée est une méthode d’apprentissage automatique (machine learning) utilisée en télédétection pour attribuer à chaque pixel d’une image satellite une classe thématique en fonction des données d’entraînement fournies par l’utilisateur.
Autrement dit, l’opérateur fournit un jeu de données de référence appelé échantillons d’entraînement : ce sont des zones du territoire où la classe est connue avec certitude (par exemple, une parcelle forestière, une zone urbaine, un lac, etc.). Ces données permettent à un algorithme de « s’entraîner » pour reconnaître les caractéristiques spectrales spécifiques à chaque classe.
L’algorithme applique ensuite ce modèle appris à tous les pixels de l’image pour leur attribuer la classe la plus probable, produisant ainsi une carte thématique de la couverture du sol.
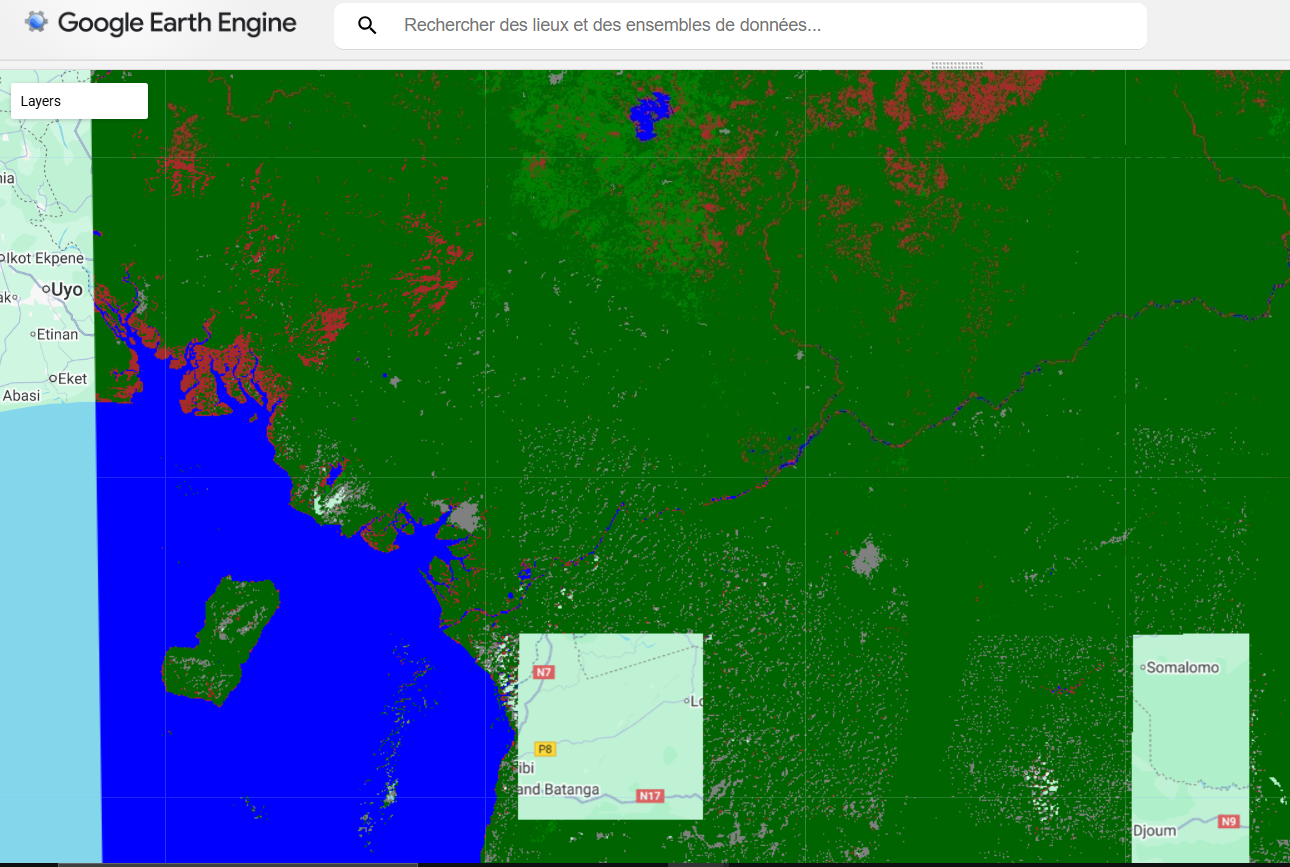
1.2. Différence avec la classification non supervisée
Contrairement à la classification supervisée, la classification non supervisée ne nécessite pas d’échantillons d’entraînement. Elle regroupe les pixels en clusters (groupes) selon leur similarité spectrale, sans savoir à quelles classes ces groupes correspondent. L’utilisateur doit ensuite interpréter ces groupes.
La classification supervisée est souvent préférée quand on a des connaissances terrain fiables, car elle produit des résultats plus précis et directement exploitables.
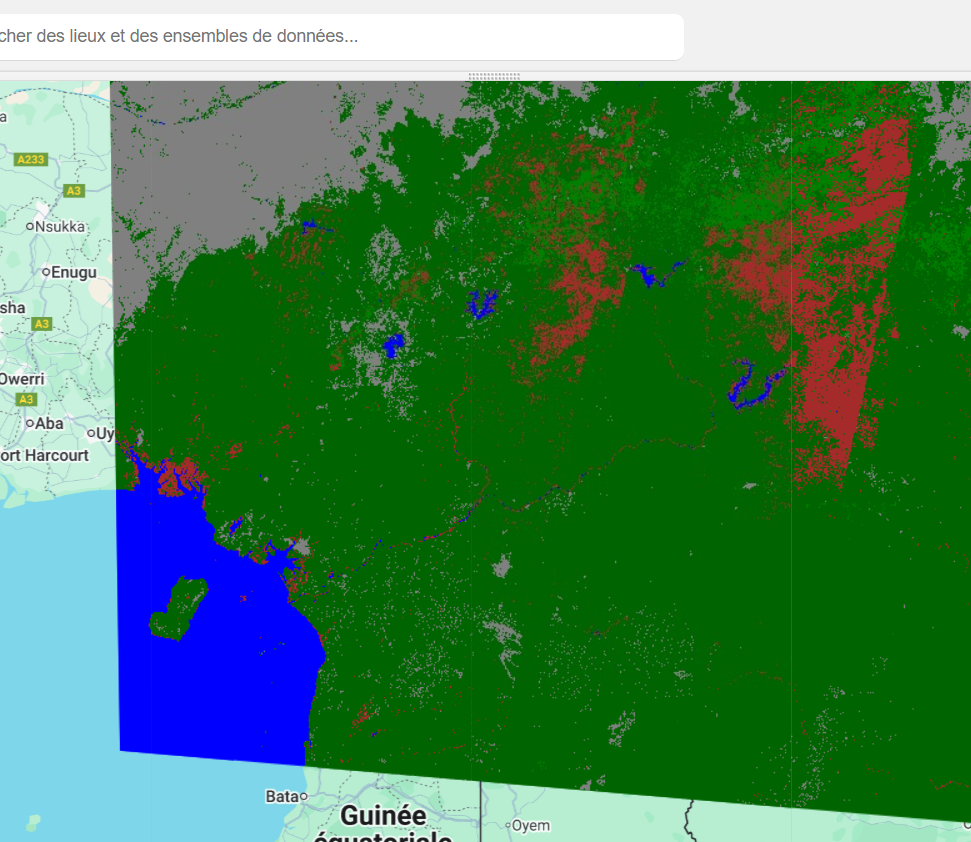
Pourquoi utiliser la classification supervisée ?
- Précision : Parce que l’utilisateur fournit des exemples réels, l’algorithme apprend des signatures spectrales exactes pour chaque classe, ce qui améliore la qualité des résultats.
- Contrôle : L’opérateur décide des classes à cartographier selon son besoin spécifique.
- Flexibilité : Adaptée à différents types d’images (Landsat, Sentinel, SPOT, etc.) et à différents contextes géographiques.
- Automatisation : Une fois entraîné, le modèle peut être appliqué sur des séries temporelles pour suivre les changements.
Étapes Clés de la Classification Supervisée
Voici un déroulé typique, étape par étape, pour réaliser une classification supervisée efficace.
3.1. Choix des classes
La première étape consiste à définir clairement les catégories à cartographier. Par exemple :
- Forêt dense
- Forêt dégradée
- Sol nu
- Zone urbaine
- Plans d’eau
Le choix des classes dépend du contexte d’étude et des objectifs.
3.2. Collecte des données d’entraînement
Il s’agit de sélectionner des zones dont la classe est connue avec certitude. Ces données peuvent provenir de plusieurs sources :
- Visites terrain
- Cartes existantes fiables
- Analyse visuelle d’images à haute résolution
- Points GPS collectés sur le terrain
Ces zones doivent être représentatives et spatialement dispersées pour couvrir la variabilité spectrale.
3.3. Prétraitement des images
Pour améliorer la classification, il est souvent nécessaire de :
- Appliquer un masque nuage (ex : Sentinel-2 avec bande QA60)
- Corriger les effets atmosphériques
- Calculer des indices spectraux utiles (NDVI, NDWI, etc.)
- Sélectionner les bandes pertinentes
3.4. Extraction des signatures spectrales
L’algorithme va extraire les valeurs spectrales des pixels dans les zones d’entraînement. Ces signatures sont la base pour apprendre à distinguer les classes.
3.5. Choix du classificateur
Différents algorithmes sont disponibles selon le logiciel et la puissance de calcul :
- CART (arbres de décision)
- Random Forest
- SVM (Support Vector Machine)
- k-NN (k plus proches voisins)
3.6. Entraînement du modèle
Le classificateur est entraîné sur les données d’entraînement, associant les signatures spectrales aux classes correspondantes.
3.7. Classification de l’image complète
Le modèle appliqué pixel par pixel permet d’attribuer une classe à chaque pixel, produisant ainsi une carte thématique.
3.8. Validation et évaluation
Pour juger de la qualité, on utilise un jeu de données indépendant (points de validation) pour calculer :
- La matrice de confusion
- La précision globale
- Le coefficient kappa
- Les précisions par classe
Les principaux algorithmes utilisés
4.1. CART (Classification and Regression Trees)
Un algorithme simple et rapide. Il construit un arbre décisionnel qui sépare les classes selon des seuils sur les bandes spectrales. Facile à interpréter, mais peut être sensible au surapprentissage.
4.2. Random Forest
C’est un ensemble de plusieurs arbres de décision. Plus robuste que CART, il offre généralement une meilleure précision. C’est un des algorithmes les plus populaires pour la classification supervisée.
4.3. SVM (Support Vector Machines)
Très efficace pour séparer des classes complexes et non linéaires. Plus gourmand en ressources, il nécessite parfois un réglage précis des paramètres.
4.4. k-NN (k plus proches voisins)
Classe un pixel selon la classe majoritaire de ses voisins les plus proches dans l’espace spectral. Simple, mais sensible au bruit et aux données d’entraînement.
Avantages et Limites
5.1. Avantages
- Haute précision si les données d’entraînement sont bonnes
- Possibilité d’analyser des séries temporelles pour détecter les changements
- Large panel d’algorithmes adaptés à différents besoins
- Large disponibilité des outils logiciels gratuits (Google Earth Engine, QGIS…)
5.2. Limites
- Nécessite des données d’entraînement de qualité et représentatives
- Les classes doivent être spectrales différentes
- Sensibilité aux erreurs d’étiquetage dans les données d’entraînement
- Nécessité de validation rigoureuse pour éviter des erreurs d’interprétation
- Peut être difficile à appliquer dans des zones avec des classes très similaires spectralement
6. Applications concrètes
6.1. Surveillance forestière
Identification des zones dégradées ou déboisées pour la gestion durable. Suivi des surfaces forestières dans le temps.
6.2. Cartographie urbaine
Délimitation des zones bâties, des espaces verts, pour l’aménagement urbain.
6.3. Agriculture de précision
Classification des types de cultures, détection des sols nus, suivi de la santé des cultures.
6.4. Gestion de l’eau
Cartographie des plans d’eau, des zones inondables, suivi des zones humides.